MongoDB Atlas Sink Connector for Confluent Cloud¶
The fully-managed MongoDB Atlas Sink connector for Confluent Cloud maps and persists events from Apache Kafka® topics directly to a MongoDB Atlas database collection. The connector supports Avro, JSON Schema, Protobuf, JSON (schemaless), String, or BSON data from Apache Kafka® topics. The connector ingests events from Kafka topics directly into a MongoDB Atlas database, exposing the data to services for querying, enrichment, and analytics.
Note
- This Quick Start is for the fully-managed Confluent Cloud connector. If you are installing the connector locally for Confluent Platform, see MongoDB Kafka Connector documentation.
- If you require private networking for fully-managed connectors, make sure to set up the proper networking beforehand. For more information, see Manage Networking for Confluent Cloud Connectors.
Features¶
Note that MongoDB Atlas Sink connector supports MongoDB Atlas only and will not work with a self-managed MongoDB database.
The connector provides the following features:
Collections: Collections can be auto-created based on topic names.
Database authentication: Uses password authentication.
Input data formats: The connector supports Avro, JSON Schema, Protobuf, JSON (schemaless), String, or BSON input data formats. Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf). See Schema Registry Enabled Environments for additional information.
Select configuration properties:
"max.num.retries": How often retries should be attempted on write errors."max.batch.size": The maximum number of sink records to batch together for processing."delete.on.null.values": Whether the connector should delete documents with matching key values when the value is null."doc.id.strategy": The strategy to generate a unique document ID (_id)."write.strategy": Defines the behavior of bulk write operations made on a MongoDB collection.
See Configuration Properties for all property values and definitions.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Connect Usage Examples section.
Limitations¶
Be sure to review the following information.
- For connector limitations, see MongoDB Atlas Sink Connector limitations.
- If you plan to use one or more Single Message Transforms (SMTs), see SMT Limitations.
- If you plan to use Confluent Cloud Schema Registry, see Schema Registry Enabled Environments.
Quick Start¶
Use this quick start to get up and running with the Confluent Cloud MongoDB Atlas sink connector. The quick start provides the basics of selecting the connector and configuring it to consume data from Kafka and persist the data to a MongoDB database.
Note
This connector supports MongoDB Atlas only and will not work with a self-managed MongoDB database.
- Prerequisites
- Authorized access to a Confluent Cloud cluster on Amazon Web Services (AWS), Microsoft Azure (Azure), or Google Cloud.
- The Confluent CLI installed and configured for the cluster. See Install the Confluent CLI.
- Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf). See Schema Registry Enabled Environments for additional information.
- Access to a MongoDB database.
- The MongoDB database service endpoint and the Kafka cluster must be in the same region.
- The MongoDB hostname address must provide a service record (SRV). A standard connection string does not work.
- For networking considerations, see Networking and DNS. To use a set of public egress IP addresses, see Public Egress IP Addresses for Confluent Cloud Connectors.
- If you have a VPC-peered cluster in Confluent Cloud, consider configuring a PrivateLink Connection between MongoDB Atlas and the VPC.
- Kafka cluster credentials. The following lists the different ways you can provide credentials.
- Enter an existing service account resource ID.
- Create a Confluent Cloud service account for the connector. Make sure to review the ACL entries required in the service account documentation. Some connectors have specific ACL requirements.
- Create a Confluent Cloud API key and secret. To create a key and secret, you can use confluent api-key create or you can autogenerate the API key and secret directly in the Cloud Console when setting up the connector.
Adding an IP Whitelist Entry¶
Important
- For networking considerations, see Networking and DNS.
- To use a set of public egress IP addresses, see Public Egress IP Addresses for Confluent Cloud Connectors.
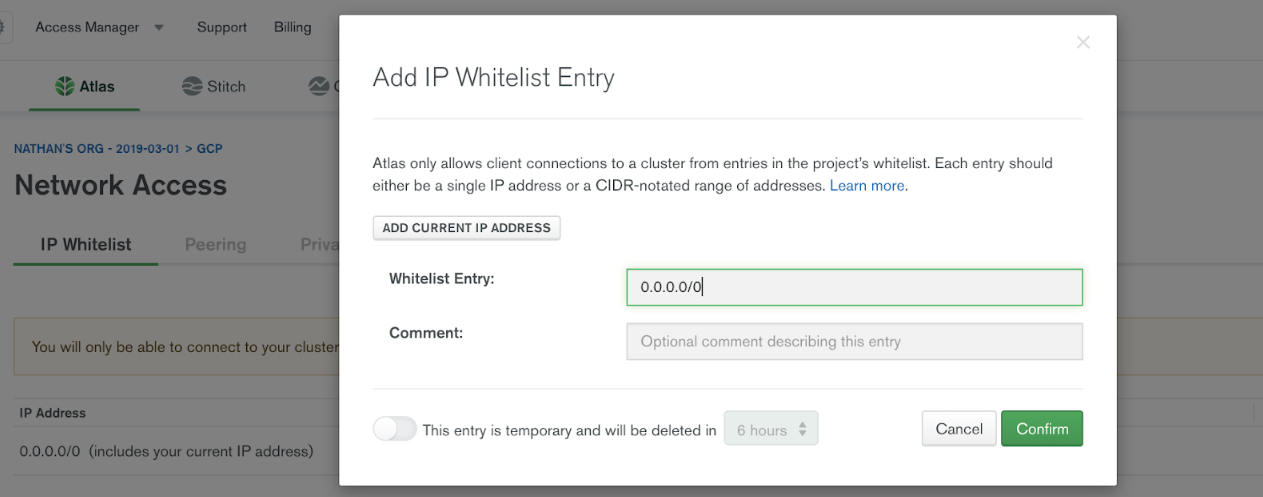
By default, MongoDB Atlas does not allow external network connections from the Internet. To allow external connections, you can add a specific IP or a CIDR IP range using the IP Whitelist entry dialog box under the Network Access menu in MongoDB.
In order for Confluent Cloud to connect to MongoDB Atlas, you need to specify the public IP address of your Confluent Cloud cluster. Add all of the Confluent Cloud egress IP addresses to the whitelist entry to your MongoDB Atlas cluster.
Using the Confluent Cloud Console¶
Step 1: Launch your Confluent Cloud cluster¶
See the Quick Start for Confluent Cloud for installation instructions.
Step 2: Add a connector¶
In the left navigation menu, click Connectors. If you already have connectors in your cluster, click + Add connector.
Step 4: Enter the connector details¶
Note
- Ensure you have all your prerequisites completed.
- An asterisk ( * ) designates a required entry.
At the Add MongoDB Atlas Sink Connector screen, complete the following:
If you’ve already populated your Kafka topics, select the topics you want to connect from the Topics list.
To create a new topic, click +Add new topic.
- Select the way you want to provide Kafka Cluster credentials. You can
choose one of the following options:
- My account: This setting allows your connector to globally access everything that you have access to. With a user account, the connector uses an API key and secret to access the Kafka cluster. This option is not recommended for production.
- Service account: This setting limits the access for your connector by using a service account. This option is recommended for production.
- Use an existing API key: This setting allows you to specify an API key and a secret pair. You can use an existing pair or create a new one. This method is not recommended for production environments.
Note
Freight clusters support only service accounts for Kafka authentication.
- Click Continue.
- Under MongoDB Atlas credentials, enter the following MongoDB Atlas
credentials:
- Connection host: Use only the hostname and not a full URL. For
example:
cluster4-r5q3r7.gcp.mongodb.net. The hostname address must provide a service record (SRV). A standard connection string does not work. - Connection user: The MongoDB Atlas connection user.
- Connection password: The MongoDB Atlas connection password. When entering the password, make sure that any special characters are URL encoded.
- Connection host: Use only the hostname and not a full URL. For
example:
- Under MongoDB Atlas Database Details, enter the following MongoDB
Atlas database details:
- Database name: The MongoDB Atlas database name.
- Collection name: The collection name to write to. If the connector is sinking data from multiple topics, this is the default collection the topics are mapped to.
- Click Continue.
Note
See Configuration Properties for all property values and definitions.
Select the Input Kafka record value format (data coming from the Kafka topic): AVRO, JSON_SR (JSON Schema), PROTOBUF, JSON (schemaless), STRING or BSON. A valid schema must be available in Schema Registry to use a schema-based message format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
Show advanced configurations
Schema context: Select a schema context to use for this connector, if using a schema-based data format. This property defaults to the Default context, which configures the connector to use the default schema set up for Schema Registry in your Confluent Cloud environment. A schema context allows you to use separate schemas (like schema sub-registries) tied to topics in different Kafka clusters that share the same Schema Registry environment. For example, if you select a non-default context, a Source connector uses only that schema context to register a schema and a Sink connector uses only that schema context to read from. For more information about setting up a schema context, see What are schema contexts and when should you use them?.
Consumer configuration
Max poll interval(ms): Set the maximum delay between subsequent consume requests to Kafka. Use this property to improve connector performance in cases when the connector cannot send records to the sink system. The default is 300,000 milliseconds (5 minutes).
Max poll records: Set the maximum number of records to consume from Kafka in a single request. Use this property to improve connector performance in cases when the connector cannot send records to the sink system. The default is 500 records.
Input messages
Change data capture handler: Sets the class name of CDC handler to use for processing. You can capture CDC events with this connector and perform corresponding insert, update, and delete operations to a destination MongoDB cluster. Valid options are
None,MongoDbChangeStreamHandler,DebeziumMongoDbHandler,DebeziumMySqlHandler,DebeziumPostgresHandler, orQlikRdbmsHandler. If not used, this property defaults toNone. For more information, see mongodb-sink-cdc.Value Subject Name Strategy: Determines how to construct the subject name under which the value schema is registered with Schema Registry. This property defaults to
TopicNameStrategy. Set this property toRecordNameStrategyto derive the subject name from the record name. For more information, see Subject name strategy.
Connection details
Max number of retries: Enter the maximum number of retries on a write error. The default value is 3 retries.
Retry defer timeout (ms): Enter value in milliseconds (ms) that a retry gets deferred. The default is 5000 ms (5 seconds).
Writes
Delete on null values: Select whether or not the connector deletes documents with matching key values when the value is null. The default is false.
Write Model Strategy: The class that specifies the
WriteModelto use for bulk writes. Defaults toDefaultWriteModelStrategy. Valid entries areDefaultWriteModelStrategy,ReplaceOneDefaultStrategy,InsertOneDefaultStrategy,ReplaceOneBusinessKeyStrategy,DeleteOneDefaultStrategy,UpdateOneTimestampsStrategy,UpdateOneBusinessKeyTimestampStrategy, orUpdateOneDefaultStrategy. For time-series collections, theDefaultWriteModelStrategywill internally default toInsertOneDefaultStrategy. For normal collections, it defaults toReplaceOneDefaultStrategy. For detailed information about each write strategy, see Strategies.Max batch size: Enter the maximum number of records to batch together for processing. The default is
0(uses the server default setting).Use ordered bulk writes: When batch processing is used, this property sets whether the connector writes the batches using ordered bulk writes. Defaults to
true.Rate limiting timeout: After a rate limit is reached, this sets how long in milliseconds (ms) the connector waits before continuing to process data. Defaults to
0.Rate limiting batch number: The number of processed batches that trigger a rate limit. Defaults to
0(that is, no rate limiting).
ID strategies
Document ID Strategy: Select the strategy to generate a unique document ID
_id. To delete a document when the value is null, this has to be set toFullKeyStrategy,PartialKeyStrategy, orProvidedInKeyStrategy. The default isBsonOidStrategy. For more information, see DocumentIdAdder.Document ID strategy overwrite existing: Whether the connector should overwrite existing values in the
_idfield when the strategy defined indoc.id.strategyis applied.Document ID strategy UUID format: The BSON output format when using
UuidStrategy. Options areStringorBinary.Document ID strategy key projection type: For use with the
PartialKeyStrategy. Allows custom key fields to be projected for the ID strategy. Use eitherAllowListorBlockList.Document ID strategy key projection list: For use with the
PartialKeyStrategy. Allows custom key fields to be projected for the ID strategy. A comma-separated list of fields names for key projection.Document ID strategy value projection type: For use with the
PartialValueStrategy. Allows custom value fields to be projected for the ID strategy. Use eitherAllowListorBlockList.Document ID strategy value projection list: For use with the
PartialValueStrategy. Allows custom value fields to be projected for the ID strategy. A comma-separated list of field names for value projection.
Time Series configuration
Timefield: The name of the top-level time field that contains the date in each time-series document. Setting this config will create a time-series collection where each document will have a BSON date value for the time field. Time-series collections were introduced in MongoDB v5.0, which is only available for dedicated clusters in MongoDB Atlas.
Auto Conversion: Whether to convert the data in the time field to BSON date format. Supported formats include integer, long and string.
Auto Convert Date Format: The string pattern to convert the source data from format to convert the source data from. The setting expects the string representation to contain both date and time information and uses the Java DateTimeFormatter.ofPattern(pattern, locale) API for the conversion. If the string only contains date information, then the time since epoch is from the start of that day. If a string representation does not contain time-zone offset, then the setting interprets the extracted date and time as UTC.
Locate Language Tag: The
DateTimeFormatterlocale language tag to use with the date pattern.Metafield: The name of the top-level field that contains metadata in each time-series document. The metadata in the specified field should be data that is used to label a unique series of documents. The field can be of any type except array.
Expire After Seconds: The amount of seconds the data remains in MongoDB before MongoDB deletes it. Omitting this field means data will not be deleted automatically.
Granularity: The expected interval between subsequent measurements for a time-series. Set this to
Noneor leave it empty if the data is not time-series.
Server API
Server API version: The MongoDB server API version to use. This property is disabled by default.
Deprecation errors: Whether or not to require the connector to report the use of deprecated server APIs as errors. This property is disabled by default.
Strict: Whether or not to require strict server API version enforcement. This property is disabled by default.
Namespace mapping
Namespace mapper class: The class that determines the namespace where the connector sinks data. Defaults to
DefaultNamespaceMapper, which is based on the database configuration and either the topic name or the collection configuration. Can be set toFieldPathNamespaceMapper, which is based on the data’s field values. For more information, see the MongoDB documentation.Key field for destination database name: The name of the key document field that specifies the name of the database to write to.
Key field for database collection name: The name of the key document field that specifies the name of the collection to write to.
Value field for destination database name: The name of the value document field that specifies the name of the database to write to.
Value field for destination collection name: The name of the value document field that specifies the name of the collection to write to.
Mapped field error: Whether to throw an exception when either the document is missing the mapped field or it has an invalid BSON type. When set to
true, the connector does not process documents missing the mapped field or containing an invalid BSON type. Defaults tofalse.
Transforms
Single Message Transforms: To add a new SMT, see Add transforms. For more information about unsupported SMTs, see Unsupported transformations.
Processing position
Set offsets: To define a specific offset, see Manage offsets.
Click Continue.
Based on the number of topic partitions you select, you will be provided with a recommended number of tasks. One task can handle up to 100 partitions.
- To change the number of recommended tasks, enter the number of tasks for the connector to use in the Tasks field.
- Click Continue.
Review the configuration summary and verify the following:
Verify the connection details and click Launch.
The status for the connector should go from Provisioning to Running. It may take a few minutes.

Step 5: Check MongoDB¶
After the connector is running, verify that messages are populating your MongoDB database.
Tip
When you launch a connector, a Dead Letter Queue topic is automatically created. See View Connector Dead Letter Queue Errors in Confluent Cloud for details.
Using the Confluent CLI¶
Complete the following steps to set up and run the connector using the Confluent CLI.
Note
Make sure you have all your prerequisites completed.
Step 1: List the available connectors¶
Enter the following command to list available connectors:
confluent connect plugin list
Step 2: List the connector configuration properties¶
Enter the following command to show the connector configuration properties:
confluent connect plugin describe <connector-plugin-name>
The command output shows the required and optional configuration properties.
Step 3: Create the connector configuration file¶
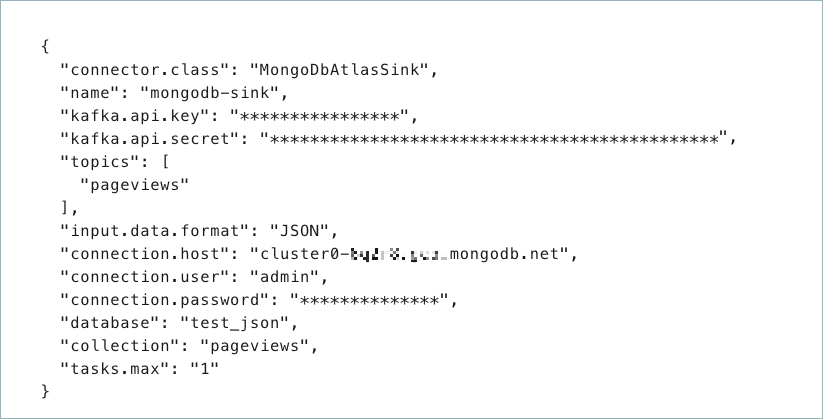
Create a JSON file that contains the connector configuration properties. The following example shows the required connector properties.
{
"connector.class": "MongoDbAtlasSink",
"name": "confluent-mongodb-sink",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "<my-kafka-api-key",
"kafka.api.secret": "<my-kafka-api-secret>",
"input.data.format" : "JSON",
"connection.host": "<database-host-address>",
"connection.user": "<my-username>",
"connection.password": "<my-password>",
"topics": "<kafka-topic-name>",
"max.num.retries": "3",
"retries.defer.timeout": "5000",
"max.batch.size": "0",
"database": "<database-name>",
"collection": "<collection-name>",
"tasks.max": "1"
}
Note the following property definitions:
"connector.class": Identifies the connector plugin name."name": Sets a name for your new connector.
"kafka.auth.mode": Identifies the connector authentication mode you want to use. There are two options:SERVICE_ACCOUNTorKAFKA_API_KEY(the default). To use an API key and secret, specify the configuration propertieskafka.api.keyandkafka.api.secret, as shown in the example configuration (above). To use a service account, specify the Resource ID in the propertykafka.service.account.id=<service-account-resource-ID>. To list the available service account resource IDs, use the following command:confluent iam service-account list
For example:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"input.data.format": Sets the input Kafka record value format (data coming from the Kafka topic). Valid entries are AVRO, JSON_SR, PROTOBUF, JSON, STRING, or BSON. You must have Confluent Cloud Schema Registry configured if using a schema-based message format (for example, Avro, JSON_SR (JSON Schema), or Protobuf)."connection.host": The MongoDB host. Use a hostname address and not a full URL. For example:cluster4-r5q3r7.gcp.mongodb.net. The hostname address must provide a service record (SRV). A standard connection string does not work."collection": The MongoDB collection name. For multiple topics, this is the default collection the topics are mapped to.The following are optional (with the exception of the number of tasks).
"max.num.retries": How often retries should be attempted on write errors. If not used, this property defaults to 3."retries.defer.timeout": How long (in milliseconds) a retry should get deferred. If not used, the default is 5000 ms."max.batch.size": The maximum number of sink records to batch together for processing. If not used, this property defaults to 0."delete.on.null.values": Whether the connector should delete documents with matching key values, when the value is null. If not used, this property defaults tofalse."doc.id.strategy": Sets the strategy to generate a unique document ID(_id). Enter the strategy to generate a unique document ID (_id). Valid entries areBsonOidStrategy,KafkaMetaDataStrategy,FullKeyStrategy,PartialKeyStrategy,PartialValueStrategy,ProvidedInKeyStrategy,ProvidedInValueStrategy, orUuidStrategy. To delete the document when the value is null, you must set the strategy toFullKeyStrategy,PartialKeyStrategy, orProvidedInKeyStrategy. The default value isBsonOidStrategy. For more information, see DocumentIdAdder.Depending on the selected strategy, add the appropriate Document ID strategy projection list:
"key.projection.type": For use withPartialKeyStrategy. Use eitherallowlistorblocklistto allow or block the custom key fields to be projected for ID strategy. If not used, this property defaults tonone."key.projection.list": For use withPartialKeyStrategy. A comma-separated list of key fields to be projected for ID strategy."value.projection.type": For use withPartialValueStrategy. Use eitherallowlistorblocklistto allow or block the custom value fields to be projected for ID strategy. If not used, this property defaults tonone."value.projection.list": For use withPartialValueStrategy. A comma-separated list of value fields to be projected for ID strategy.
"write.strategy": Sets the write model for bulk write operations. Valid entries areDefaultWriteModelStrategy,ReplaceOneDefaultStrategy,InsertOneDefaultStrategy,ReplaceOneBusinessKeyStrategy,DeleteOneDefaultStrategy,UpdateOneTimestampsStrategy,UpdateOneBusinessKeyTimestampStrategy, orUpdateOneDefaultStrategy. If not used, this property defaults toDefaultWriteModelStrategy. For time-series collections, theDefaultWriteModelStrategywill internally default toInsertOneDefaultStrategy. For normal collections, it defaults toReplaceOneDefaultStrategy. For detailed information about each write strategy, see Strategies."cdc.handler": Sets the class name of CDC handler to use for processing. You can capture CDC events with the MongoDB Kafka Sink connector and perform corresponding insert, update, and delete operations to a destination MongoDB cluster. Valid entries areNone,MongoDbChangeStreamHandler,DebeziumMongoDbHandler,DebeziumMySqlHandler,DebeziumPostgresHandler, orQlikRdbmsHandler. If not used, this property defaults toNone. For more information, see mongodb-sink-cdc."timeseries.timefield": Sets the name of the top-level time field that contains the date in each time-series document. Setting this property will create a time-series collection where each document will have a BSON date as the value for the time field. Time-series collections were introduced in MongoDB v5.0, which is only available for dedicated clusters in MongoDB Atlas."timeseries.timefield.auto.convert": Whether to convert the data in the time field to BSON date format. Supported formats for data include integer, long and string. If not used, this property defaults tofalse."timeseries.timefield.auto.convert.date.format": Sets the DateTimeFormatter format to convert the source data from. The setting expects the string representation to contain both date and time information and uses the Java DateTimeFormatter.ofPattern(pattern, locale) API for the conversion. If the string only contains date information, then the time since epoch is from the start of that day. If a string representation does not contain time-zone offset, then the setting interprets the extracted date and time as UTC. If not used, this property defaults toyyyy-MM-dd[['T'][ ]][HH:mm:ss[[.][SSSSSS][SSS]][ ]VV[ ]'['VV']'][HH:mm:ss[[.][SSSSSS][SSS]][ ]X][HH:mm:ss[[.][SSSSSS][SSS]]]."timeseries.timefield.auto.convert.locale.language.tag": Sets the DateTimeFormatter locale language tag to use with the date pattern. See Language tags in HTML and XML for more information on constructing tags. If not used, this property defaults toen."timeseries.metafield": Sets the name of the top-level field that contains metadata in each time-series document. The metadata in the specified field should be data that is used to label a unique series of documents. The field can be of any type except array."timeseries.expire.after.seconds": Sets the number of seconds after which the document expires. MongoDB deletes expired documents automatically. If not used, this property default to0, which means data will not be deleted automatically."ts.granularity": Sets the interval granularity for subsequent measurements for a time-series. Valid entries areNone,seconds,minutes, orhours. If not used, this property defaults toNone. For normal collections,Noneis the only applicable value. For time-series collections, all entries are applicable andNoneinternally defaults toseconds.Enter the number of tasks for the connector. Refer to Confluent Cloud connector limitations for additional information.
Single Message Transforms: See the Single Message Transforms (SMT) documentation for details about adding SMTs using the CLI.
See Configuration Properties for all property values and definitions.
Step 4: Load the properties file and create the connector¶
Enter the following command to load the configuration and start the connector:
confluent connect cluster create --config-file <file-name>.json
For example:
confluent connect cluster create --config-file mongo-db-sink.json
Example output:
Created connector confluent-mongodb-sink lcc-ix4dl
Step 5: Check the connector status¶
Enter the following command to check the connector status:
confluent connect cluster list
Example output:
ID | Name | Status | Type
+-----------+-------------------------+---------+------+
lcc-ix4dl | confluent-mongodb-sink | RUNNING | sink
Step 6: Check MongoDB¶
After the connector is running, verify that records are populating your MongoDB database.
Tip
When you launch a connector, a Dead Letter Queue topic is automatically created. See View Connector Dead Letter Queue Errors in Confluent Cloud for details.
Configuration Properties¶
Use the following configuration properties with the fully-managed connector. For self-managed connector property definitions and other details, see the connector docs in Self-managed connectors for Confluent Platform.
How should we connect to your data?¶
nameSets a name for your connector.
- Type: string
- Valid Values: A string at most 64 characters long
- Importance: high
Schema Config¶
schema.context.nameAdd a schema context name. A schema context represents an independent scope in Schema Registry. It is a separate sub-schema tied to topics in different Kafka clusters that share the same Schema Registry instance. If not used, the connector uses the default schema configured for Schema Registry in your Confluent Cloud environment.
- Type: string
- Default: default
- Importance: medium
Input messages¶
input.data.formatSets the input Kafka record value format. Valid entries are AVRO, JSON_SR, PROTOBUF, JSON, STRING or BSON. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO, JSON_SR, and PROTOBUF.
- Type: string
- Importance: high
cdc.handlerThe class name of the CDC handler to use for processing. You can capture CDC events with the MongoDB Kafka sink connector and perform corresponding insert, update, and delete operations to a destination MongoDB cluster.
- Type: string
- Default: None
- Importance: low
value.subject.name.strategyDetermines how to construct the subject name under which the value schema is registered with Schema Registry.
- Type: string
- Default: TopicNameStrategy
- Valid Values: RecordNameStrategy, TopicNameStrategy
- Importance: medium
replace.null.with.defaultWhether to replace fields that have a default value and that are null to the default value. When set to true, the default value is used, otherwise null is used.
- Type: boolean
- Default: true
- Importance: medium
schemas.enableInput messages must contain schema and payload fields and may not contain additional fields. For plain JSON data, set this to false
- Type: boolean
- Default: false
- Importance: medium
ignore.default.for.nullablesWhen set to true, this property ensures that the corresponding record in Kafka is NULL, instead of showing the default column value.
- Type: boolean
- Default: false
- Importance: medium
Writes¶
delete.on.null.valuesWhether or not the connector should try to delete documents based on key when value is null.
- Type: boolean
- Default: false
- Importance: low
max.batch.sizeThe maximum number of sink records to possibly batch together for processing.
- Type: int
- Default: 0
- Valid Values: [0,…]
- Importance: low
bulk.write.orderedWhether the batches controlled by ‘max.batch.size’ must be written via ordered bulk writes.
- Type: boolean
- Default: true
- Importance: low
rate.limiting.timeoutHow long in ms processing should wait before continuing after triggering a rate limit.
- Type: int
- Default: 0
- Importance: low
rate.limiting.every.nThe number of processed batches that will trigger rate limiting. The default value of 0 sets no rate limiting.
- Type: int
- Default: 0
- Importance: low
write.strategyThe class that specifies the WriteModel to use for bulk writes.
- Type: string
- Default: DefaultWriteModelStrategy
- Importance: low
Kafka Cluster credentials¶
kafka.auth.modeKafka Authentication mode. It can be one of KAFKA_API_KEY or SERVICE_ACCOUNT. It defaults to KAFKA_API_KEY mode.
- Type: string
- Default: KAFKA_API_KEY
- Valid Values: KAFKA_API_KEY, SERVICE_ACCOUNT
- Importance: high
kafka.api.keyKafka API Key. Required when kafka.auth.mode==KAFKA_API_KEY.
- Type: password
- Importance: high
kafka.service.account.idThe Service Account that will be used to generate the API keys to communicate with Kafka Cluster.
- Type: string
- Importance: high
kafka.api.secretSecret associated with Kafka API key. Required when kafka.auth.mode==KAFKA_API_KEY.
- Type: password
- Importance: high
Which topics do you want to get data from?¶
topicsIdentifies the topic name or a comma-separated list of topic names.
- Type: list
- Importance: high
How should we connect to your MongoDB Atlas database?¶
connection.hostMongoDB Atlas connection host (e.g. confluent-test.mycluster.mongodb.net).
- Type: string
- Importance: high
connection.userMongoDB Atlas connection user.
- Type: string
- Importance: high
connection.passwordMongoDB Atlas connection password.
- Type: password
- Importance: high
databaseMongoDB Atlas database name.
- Type: string
- Importance: high
Database details¶
collectionCollection name to write to. If the connector is sinking data from multiple topics, this is the default collection the topics are mapped to.
- Type: string
- Importance: medium
ID strategies¶
doc.id.strategyThe IdStrategy class name to use for generating a unique document id (_id).
- Type: string
- Default: BsonOidStrategy
- Importance: low
doc.id.strategy.overwrite.existingWhether the connector should overwrite existing values in the _id field when the strategy defined in doc.id.strategy is applied.
- Type: boolean
- Default: false
- Importance: low
document.id.strategy.uuid.formatThe bson output format when using the UuidStrategy. Can be either String or Binary.
- Type: string
- Default: string
- Importance: low
key.projection.typeFor use with the PartialKeyStrategy allows custom key fields to be projected for the ID strategy. Use either AllowList or BlockList.
- Type: string
- Default: none
- Importance: low
key.projection.listFor use with the PartialKeyStrategy allows custom key fields to be projected for the ID strategy. A comma-separated list of field names for key projection.
- Type: string
- Importance: low
value.projection.typeFor use with the PartialValueStrategy allows custom value fields to be projected for the ID strategy. Use either AllowList or BlockList.
- Type: string
- Default: none
- Importance: low
value.projection.listFor use with the PartialValueStrategy allows custom value fields to be projected for the ID strategy. A comma-separated list of field names for value projection.
- Type: string
- Importance: low
Namespace mapping¶
namespace.mapper.classThe class that determines the namespace to write the sink data to. By default this will be based on the ‘database’ configuration and either the topic name or the ‘collection’ configuration.
- Type: string
- Default: DefaultNamespaceMapper
- Importance: low
namespace.mapper.key.database.fieldThe key field to use as the destination database name.
- Type: string
- Importance: low
namespace.mapper.key.collection.fieldThe key field to use as the destination collection name.
- Type: string
- Importance: low
namespace.mapper.value.database.fieldThe value field to use as the destination database name.
- Type: string
- Importance: low
namespace.mapper.value.collection.fieldThe value field to use as the destination collection name.
- Type: string
- Importance: low
namespace.mapper.error.if.invalidWhether to throw an error if the mapped field is missing or invalid. Defaults to false.
- Type: boolean
- Default: false
- Importance: low
Server API¶
server.api.versionThe server API version to use. Disabled by default.
- Type: string
- Importance: low
server.api.deprecation.errorsSets whether the connector requires use of deprecated server APIs to be reported as errors.
- Type: boolean
- Default: false
- Importance: low
server.api.strictSets whether the application requires strict server API version enforcement.
- Type: boolean
- Default: false
- Importance: low
Connection details¶
max.num.retriesHow many retries should be attempted on write errors.
- Type: int
- Default: 3
- Valid Values: [0,…]
- Importance: low
retries.defer.timeoutHow long a retry should get deferred.
- Type: int
- Default: 5000
- Valid Values: [0,…]
- Importance: low
Time Series configuration¶
timeseries.timefieldThe name of the top-level field which contains the date in each time series document. Setting this config will create a time series collection where each document will have a BSON date as the value for the timefield.
- Type: string
- Default: “”
- Importance: low
timeseries.timefield.auto.convertWhether to convert the data in the field into a BSON Date format. Supported formats include integer, long, and string.
- Type: boolean
- Default: false
- Importance: low
timeseries.timefield.auto.convert.date.formatThe string pattern to convert the source data from. The setting expects the string representation to contain both date and time information and uses the Java DateTimeFormatter.ofPattern(pattern, locale) API for the conversion. If the string only contains date information, then the time since epoch is from the start of that day. If a string representation does not contain time-zone offset, then the setting interprets the extracted date and time as UTC.
- Type: string
- Default: yyyy-MM-dd[[‘T’][ ]][HH:mm:ss[[.][SSSSSS][SSS]][ ]VV[ ]’[‘VV’]’][HH:mm:ss[[.][SSSSSS][SSS]][ ]X][HH:mm:ss[[.][SSSSSS][SSS]]]
- Importance: low
timeseries.timefield.auto.convert.locale.language.tagThe DateTimeFormatter locale language tag to use with the date pattern.
- Type: string
- Default: en
- Importance: low
timeseries.metafieldThe name of the top-level field that contains metadata in each time series document. This field groups related data. It can be of any type except array.
- Type: string
- Default: “”
- Importance: low
timeseries.expire.after.secondsThe amount of seconds the data remains in MongoDB before MongoDB deletes it. Omitting this field means data will not be deleted automatically.
- Type: int
- Default: 0
- Valid Values: [0,…]
- Importance: low
ts.granularityThe expected interval between subsequent measurements for a time-series. Set this to None or leave it empty if the data is not time-series
- Type: string
- Default: None
- Importance: low
Error handling¶
mongo.errors.toleranceUse this property if you would like to configure the connector’s error handling behavior differently from the Connect framework’s.
- Type: string
- Default: NONE
- Importance: medium
Consumer configuration¶
max.poll.interval.msThe maximum delay between subsequent consume requests to Kafka. This configuration property may be used to improve the performance of the connector, if the connector cannot send records to the sink system. Defaults to 300000 milliseconds (5 minutes).
- Type: long
- Default: 300000 (5 minutes)
- Valid Values: [60000,…,1800000] for non-dedicated clusters and [60000,…] for dedicated clusters
- Importance: low
max.poll.recordsThe maximum number of records to consume from Kafka in a single request. This configuration property may be used to improve the performance of the connector, if the connector cannot send records to the sink system. Defaults to 500 records.
- Type: long
- Default: 500
- Valid Values: [1,…,500] for non-dedicated clusters and [1,…] for dedicated clusters
- Importance: low
Number of tasks for this connector¶
tasks.maxMaximum number of tasks for the connector.
- Type: int
- Valid Values: [1,…]
- Importance: high
Suggested Reading¶
Blog post: Announcing the MongoDB Atlas Sink and Source connectors in Confluent Cloud
Next Steps¶
For an example that shows fully-managed Confluent Cloud connectors in action with Confluent Cloud ksqlDB, see the Cloud ETL Demo. This example also shows how to use Confluent CLI to manage your resources in Confluent Cloud.