JSON Schema Serializer and Deserializer for Schema Registry on Confluent Cloud¶
This document describes how to use JSON Schema with the Apache Kafka® Java client and console tools.
The Confluent Schema Registry based JSON Schema serializer, by design, does not include the message schema; but rather, includes the schema ID (in addition to a magic byte) followed by the normal binary encoding of the data itself. You can choose whether or not to embed a schema inline; allowing for cases where you may want to communicate the schema offline, with headers, or some other way. This is in contrast to other systems, such as Hadoop, that always include the schema with the message data. To learn more, see Wire format.
Both the JSON Schema serializer and deserializer can be configured to fail if
the payload is not valid for the given schema. This is set by specifying
json.fail.invalid.schema=true. By default, this property is set to false.
The examples below use the default hostname and port for the Kafka bootstrap server (localhost:9092) and Schema Registry (localhost:8081).
Supported JSON Schema specifications¶
For Confluent Platform version 7.6.0, the following JSON Schema specifications are fully supported:
- Draft 04
- Draft 06
- Draft 07
From Confluent Platform 7.6.0 and later, the following JSON Schema specifications are fully supported:
- Draft 04
- Draft 06
- Draft 07
- Draft 2020-12
You can use the configuration option json.schema.spec.version to indicate the specification version to use for JSON schemas derived from objects. Support is provided for schema draft versions 4 and later,
as described in the first bullet under JSON Schema serializer. Notes on the drafts can be found in the JSON Schema Specification.
JSON Schema serializer¶
Plug the KafkaJsonSchemaSerializer into KafkaProducer to send messages of JSON Schema type to Kafka.
Assuming you have a Java class that is decorated with Jackson annotations, such as the following:
public static class User {
@JsonProperty
public String firstName;
@JsonProperty
public String lastName;
@JsonProperty
public short age;
public User() {}
public User(String firstName, String lastName, short age) {
this(firstName, lastName, age, null);
}
}
You can serialize User objects as follows:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"io.confluent.kafka.serializers.json.KafkaJsonSchemaSerializer");
props.put("schema.registry.url", "http://127.0.0.1:8081");
Producer<String, User> producer = new KafkaProducer<String, User>(props);
String topic = "testjsonschema";
String key = "testkey";
User user = new User("John", "Doe", 33);
ProducerRecord<String, User> record
= new ProducerRecord<String, User>(topic, key, user);
producer.send(record).get();
producer.close();
The following additional configurations are available for JSON Schemas derived from Java objects:
json.schema.spec.versionIndicates the specification version to use for JSON schemas derived from objects. Support is provided for schema draft versions 4 and later. At the time of this writing, valid values are one of the following strings:draft_4,draft_6,draft_7,draft_2019_09, ordraft_2020_12. The default isdraft_7. Supported versions per Confluent Platform release are listed in Supported JSON Schema specifications. Notes on the drafts can be found in the JSON Schema Specification.json.oneof.for.nullablesIndicates whether JSON schemas derived from objects will useoneOffor nullable fields. The default boolean value istrue.json.default.property.inclusionControls the inclusion of properties during serialization. Configured with one of the values in Jackson’s JsonInclude.Include enumeration.json.fail.unknown.propertiesIndicates whether JSON schemas derived from objects will fail if unknown properties are encountered. The default boolean value istrue.json.write.dates.iso8601Allows dates to be written as ISO-8601 strings. The default boolean value isfalse.
Using @Schema annotation on the Java object¶
Instead of having the schema derived from the Java object, you can pass a schema directly to the producer using annotations on the Java class, as shown in the following example.
@io.confluent.kafka.schemaregistry.annotations.Schema(value="{"
+ "\"$id\": \"https://acme.com/referrer.json\","
+ "\"$schema\": \"http://json-schema.org/draft-07/schema#\","
+ "\"type\":\"object\","
+ "\"properties\":{\"Ref\":"
+ "{\"$ref\":\"ref.json#/definitions/ExternalType\"}},\"additionalProperties\":false}",
refs={@io.confluent.kafka.schemaregistry.annotations.SchemaReference(
name="ref.json", subject="reference")})
public class MyObject {
...
}
Sending a JsonNode payload¶
The KafkaJsonSchemaSerializer also supports a JsonNode in envelope format,
meaning an ObjectNode with two fields: schema and payload, where schema is a
JSON Schema, and payload is a JsonNode for the payload.
byte[] serializedRecord1 = serializer.serialize(TOPIC,
JsonSchemaUtils.envelope(rawSchemaJson1, objectNode1)
JSON Schema deserializer¶
Plug KafkaJsonSchemaDeserializer into KafkaConsumer to receive messages
of any JSON Schema type from Kafka.
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "io.confluent.kafka.serializers.json.KafkaJsonSchemaDeserializer");
props.put("schema.registry.url", "http://localhost:8081");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(KafkaJsonDeserializerConfig.JSON_VALUE_TYPE, User.class.getName());
String topic = "testjsonschema";
final Consumer<String, JsonNode> consumer = new KafkaConsumer<String, JsonNode>(props);
consumer.subscribe(Arrays.asList(topic));
try {
while (true) {
ConsumerRecords<String, JsonNode> records = consumer.poll(100);
User user= mapper.convertValue(record.value(), new TypeReference<User>(){});
}
}
} finally {
consumer.close();
}
Similar to how the Avro deserializer can return an instance of a specific Avro
record type or a GenericRecord, the JSON Schema deserializer can return an
instance of a specific Java class, or an instance of JsonNode.
If the JSON Schema deserializer cannot determine a specific type, then a generic type is returned.
One way to return a specific type is to use an explicit property.
For the Json Schema deserializer, you can configure the property
KafkaJsonSchemaDeserializerConfig.JSON_VALUE_TYPE or
KafkaJsonSchemaDeserializerConfig.JSON_KEY_TYPE.
In order to allow the JSON Schema deserializer to work with topics with heterogeneous types,
you must provide additional information to the schema. Configure the deserializer with a value
for type.property that indicates the name of a top-level property on the JSON schema that
specifies the fully-qualified Java type. For example, if type.property=javaType, the JSON schema
could specify "javaType":"org.acme.MyRecord" at the top level.
When deserializing a JSON payload, the KafkaJsonSchemaDeserializer can behave in three ways:
If given a
<json.key.type>or<json.value.type>, the deserializer uses the specified type to perform deserialization.The previous configuration won’t work for
RecordNameStrategy, where more than one type of JSON message might exist in a topic. To handle this case, the deserializer can be configured with<type.property>with a value that indicates the name of a top-level property on the JSON Schema that specifies the fully-qualified Java type to be used for deserialization. For example, if<type.property>=javaType, it is expected that the JSON schema will have an additional top-level property namedjavaTypethat specifies the fully-qualified Java type. For example, when using the mbknor-jackson-jsonSchema utility to generate a JSON Schema from a Java POJO, one can use the annotation@SchemaInjectto specify the javaType:// Generate javaType property @JsonSchemaInject(strings = {@JsonSchemaString(path="javaType", value="com.acme.User")}) public static class User { @JsonProperty public String firstName; @JsonProperty public String lastName; @JsonProperty @Min(0) public short age; @JsonProperty public Optional<String> nickName; public User() {} ... }
The default for
json.value.typeisObject.class.getName(). Therefore, if no type is provided or no type can be determined, the deserializer returns aLinkedHashMapfor JSON objects or aLinkedListfor JSON arrays.If you set
json.value.type=com.fasterxml.jackson.databind.JsonNode, the deserializer returns an instance of a JacksonJsonNode.
Here is a summary of specific and generic return types for each schema format.
| Avro | Protobuf | JSON Schema | |
|---|---|---|---|
| Specific type | Generated class that implements org.apache.avro.SpecificRecord | Generated class that extends com.google.protobuf.Message | Java class (that is compatible with Jackson serialization) |
| Generic type | org.apache.avro.GenericRecord | com.google.protobuf.DynamicMessage | com.fasterxml.jackson.databind.JsonNode |
Configure expiry time for client-side schema caches¶
The following format-agnostic configuration options for cache expiry time are available on both the serializer and deserializer:
latest.cache.size- The maximum size for caches holding latest schemaslatest.cache.ttl.sec- The time to live (TTL) in seconds for caches holding latest schemas, or-1for no TTL
Test drive JSON Schema¶
To get started with JSON Schema, you can use the command line producer and consumer for JSON Schema.
The command line producer and consumer are useful for understanding how the built-in JSON Schema support works on Confluent Platform.
When you incorporate the serializer and deserializer into the code for your own producers and consumers, messages and associated schemas are processed the same way as they are on the console producers and consumers.
The suggested consumer commands include a flag to read --from-beginning to
be sure you capture the messages even if you don’t run the consumer immediately
after running the producer. If you leave off the --from-beginning flag, the
consumer will read only the last message produced during its current session.
The examples below include a few minimal configs. For full property references, see Configurations reference.
Prerequisites¶
- Prerequisites to run these examples are generally the same as those described for the Schema Registry Tutorial with the exception of Maven, which is not needed here. Also, Confluent Platform version 5.5.0 or later is required here.
- The following examples use the default Schema Registry URL value (
localhost:8081). The examples show how to configure this inline by supplying the URL as an argument to the--propertyflag in the command line arguments of the producer and consumer (--property schema.registry.url=<address of your schema registry>). Alternatively, you could set this property in$CONFLUENT_HOME/etc/kafka/server.properties, and not have to include it in the producer and consumer commands. For example:confluent.schema.registry.url=http://localhost:8081 - These examples make use of the
kafka-avro-console-producerandkafka-avro-console-consumer, which are located in$CONFLUENT_HOME/bin.
Confluent Cloud prerequisites are:
- A Confluent Cloud account
- Permission to create a topic and schema in a cluster in Confluent Cloud
- Stream Governance Package enabled
- API key and secret for Confluent Cloud cluster (
$APIKEY,$APISECRET) - API key and secret for Schema Registry (
$SR_APIKEY,$SR_APISECRET) - Schema Registry endpoint URL (
$SCHEMA_REGISTRY_URL) - Cluster ID (
$CLUSTER_ID) - Schema registry cluster ID (
$SR_CLUSTER_ID)
The examples assume that API keys, secrets, cluster IDs, and API endpoints are
stored in persistent environment variables wherever possible, and refer to them
as such. You can store these in shell variables if your setup is temporary. If
you want to return to this environment and cluster for future work, consider
storing them in a profile (such as .zsh, .bashrc, or powershell.exe profiles).
The following steps provide guidelines on these prerequisites specific to these examples. To learn more general information, see Manage Clusters.
Log in to Confluent Cloud:
confluent loginCreate a Kafka cluster in Confluent Cloud
confluent kafka cluster create <name> [flags]
For example:
confluent kafka cluster create quickstart_cluster --cloud "aws" --region "us-west-2"
Your output will include a cluster ID (in the form of
lkc-xxxxxx), show the cluster name and cluster type (in this case, “Basic”), and endpoints. Take note of the cluster ID, and store it in an environment variable such as$CLUSTER_ID.Get an API key and secret for the cluster:
confluent api-key create --resource $CLUSTER_ID
Store the API key and secret for your cluster in a safe place, such as shell environment variables:
$APIKEY,$APISECRETView Stream Governance packages and Schema Registry endpoint URL.
A Stream Governance package was enabled as a part of creating the environment.
To view governance packages, use the Confluent CLI command confluent environment list:
confluent environment list
Your output will show the environment ID, name, and associated Stream Governance packages.
To view the Stream Governance API endpoint URL, use the command confluent schema-registry cluster describe:
confluent schema-registry cluster describe
Your output will show the Schema Registry cluster ID in the form of
lsrc-xxxxxx) and endpoint URL, which is also available to you in Cloud Console on the right side panel under “Stream Governance API” in the environment. Store these in environment variables:$SR_CLUSTER_IDand$SCHEMA_REGISTRY_URL.
Create a Schema Registry API key, using the Schema Registry cluster ID (
$SR_CLUSTER_ID) from the previous step as the resource ID.confluent api-key create --resource $SR_CLUSTER_ID
Store the API key and secret for your Schema Registry in a safe place, such as shell environment variables:
$SR_APIKEYand$SR_APISECRET
Create and use schemas¶
Start Confluent Platform using the following command:
confluent local services start
Tip
- Alternatively, you can simply run
confluent local services schema-registry startwhich also startskafkaandzookeeperas dependencies. This demo does not directly reference the other services, such as Connect and Control Center. That said, you may want to run the full stack anyway to further explore, for example, how the topics and messages display on Control Center. To learn more aboutconfluent local, see Quick Start for Confluent Platform and confluent local in the Confluent CLI command reference. - The
confluent localcommands run in the background so you can re-use this command window. Separate sessions are required for the producer and consumer.
- Alternatively, you can simply run
Verify registered schema types.
Schema Registry supports arbitrary schema types. You should verify which schema types are currently registered with Schema Registry.
To do so, type the following command (assuming you use the default URL and port for Schema Registry,
localhost:8081):curl http://localhost:8081/schemas/typesThe response will be one or more of the following. If additional schema format plugins are installed, these will also be available.
["JSON", "PROTOBUF", "AVRO"]
Alternatively, use the curl
--silentflag, and pipe the command through jq (curl --silent http://localhost:8081/schemas/types | jq) to get nicely formatted output:"JSON", "PROTOBUF", "AVRO"
Use the producer to send Avro records in JSON as the message value.
The new topic,
transactions-json, will be created as a part of this producer command if it does not already exist. This command starts a producer, and creates a schema for the transactions-avro topic. The schema has two fields,idandamount.kafka-json-schema-console-producer --bootstrap-server localhost:9092 \ --property schema.registry.url=http://localhost:8081 --topic transactions-json \ --property value.schema='{"type":"object", "properties":{"id":{"type":"string"},"amount":{"type":"number"} }}'Tip
The producer does not show a
>prompt, just a blank line at which to type producer messages.Type the following command in the shell, and hit return.
{ "id":"1000", "amount":500 }Open a new terminal window, and use the consumer to read from topic
transactions-jsonand get the value of the message in JSON.kafka-json-schema-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic transactions-json --property schema.registry.url=http://localhost:8081
You should see following in the console.
{"id":"1000","amount":500}Leave this consumer running.
Use the producer to send another record as the message value, which includes a new property not explicitly declared in the schema.
JSON Schema has an open content model, which allows any number of additional properties to appear in a JSON document without being specified in the JSON schema. This is achieved with
additionalPropertiesset totrue, which is the default. If you do not explicitly disableadditionalProperties(by setting it tofalse), undeclared properties are allowed in records. These next few steps demonstrate this unique aspect of JSON Schema.Return to the producer session that is already running and send the following message, which includes a new property
"customer_id"that is not declared in the schema with which we started this producer. (Hit return to send the message.){"id":"1000","amount":500,"customer_id":"1221"}Return to your running consumer to read from topic
transactions-jsonand get the new message.You should see the new output added to the original.
{"id":"1000","amount":500} {"id":"1000","amount":500,"customer_id":"1221"}The message with the new property (
customer_id) is successfully produced and read. If you try this with the other schema formats (Avro, Protobuf), it will fail at the producer command because those specifications require that all properties be explicitly declared in the schemas.Keep this consumer running.
Start a producer and pass a JSON Schema with
additionalPropertiesexplicitly set tofalse.Return to the producer command window, and stop the producer with Ctl+C.
Type the following in the shell, and press return. This is the same producer and topic (
transactions-json) used in the previous steps. The schema is almost the same as the previous one, but in this exampleadditionalPropertiesis explicitly set to false, as a part of the schema.kafka-json-schema-console-producer --bootstrap-server localhost:9092 --property schema.registry.url=http://localhost:8081 --topic transactions-json \ --property value.schema='{"type":"object", "properties":{"id":{"type":"string"},"amount":{"type":"number"} }} "additionalProperties": false}'In another shell, use
curlto get the top-level compatibility configuration.curl --silent -X GET http://localhost:8081/config
Example result (this is the default):
{"compatibilityLevel":"BACKWARD"}Tip
If you do not update the compatibility requirements, the following step will fail on a different error than the one being demonstrated here, due to the
BACKWARDcompatibility setting. For more examples of usingcurlagainst the APIs to test and set configurations, see Schema Registry API Usage Examples.Update the compatibility requirements globally.
curl -X PUT -H "Content-Type: application/vnd.schemaregistry.v1+json" \ --data '{"compatibility": "NONE"}' \ http://localhost:8081/configThe output will be:
{"compatibilityLevel":"NONE"}Start a new producer and pass a JSON Schema with additionalProperties explicitly set to
false.(You can shut down the previous producer, and start this one in the same window.)
kafka-json-schema-console-producer --bootstrap-server localhost:9092 \ --property schema.registry.url=http://localhost:8081 --topic transactions-json \ --property value.schema='{"type":"object", "properties":{"id":{"type":"string"}, "amount":{"type":"number"} }, "additionalProperties": false}'Attempt to use the producer to send another record as the message value, which includes a new property not explicitly declared in the schema.
{ "id":"1001","amount":500,"customer_id":"this-will-break"}This will break. You will get the following error:
org.apache.kafka.common.errors.SerializationException: Error serializing JSON message ... Caused by: org.apache.kafka.common.errors.SerializationException: JSON {"id":"1001","amount":500,"customer_id":"1222"} does not match schema {"type":"object","properties":{"id":{"type":"string"},"amount":{"type":"number"}},"additionalProperties":false} at io.confluent.kafka.serializers.json.AbstractKafkaJsonSchemaSerializer.serializeImpl(AbstractKafkaJsonSchemaSerializer.java:132) ... 5 more Caused by: org.everit.json.schema.ValidationException: #: extraneous key [customer_id] is not permitted ...The consumer will continue running, but no new messages will be displayed.
This is the same behavior you would see by default if using Avro or Protobuf in this scenario.
Tip
If you want to incorporate this behavior into JSON Schema producer code for your applications, include
"additionalProperties": falseinto the schemas. Examples of this are shown in the discussion about properties in Understanding JSON Schema.Rerun the producer in default mode as before and send a follow-on message with an undeclared property.
In the producer command window, stop the producer with Ctl+C.
Run the original producer command. There is no need to explicitly declare
additionalPropertiesastrue(although you could), as this is the default.kafka-json-schema-console-producer --bootstrap-server localhost:9092 \ --property schema.registry.url=http://localhost:8081 --topic transactions-json \ --property value.schema='{"type":"object", "properties":{"id":{"type":"string"},"amount":{"type":"number"} }}'Use the producer to send another record as the message value, which again includes a new property not explicitly declared in the schema.
{ "id":"1001","amount":500,"customer_id":"1222"}Return to the consumer session to read the new message.
The consumer should still be running and reading from topic
transactions-json. You will see following new message in the console.{"id":"1001","amount":500,"customer_id":"this-will-work-again"}More specifically, if you followed all steps in order and started the consumer with the
--from-beginningflag as mentioned earlier, the consumer shows a history of all messages sent:{"id":"1000","amount":500} {"id":"1000","amount":500,"customer_id":"1221"} {"id":"1001","amount":500,"customer_id":"this-will-work-again"}In another shell, use this curl command (piped through
jqfor readability) to query the schemas that were registered with Schema Registry as versions 1 and 2.To query version 1 of the schema, type:
curl --silent -X GET http://localhost:8081/subjects/transactions-json-value/versions/1/schema | jq .
Here is the expected output for version 1:
{ "type": "object", "properties": { "id": { "type": "string" }, "amount": { "type": "number" }To query version 2 of the schema.
curl --silent -X GET http://localhost:8081/subjects/transactions-json-value/versions/2/schema | jq .
Here is the expected output for version 2:
{ "type": "object", "properties": { "id": { "type": "string" }, "amount": { "type": "number" } }, "additionalProperties": false }View the latest version of the schema in more detail by running this command.
curl --silent -X GET http://localhost:8081/subjects/transactions-json-value/versions/latest | jq .
Here is the expected output of the above command:
"subject": "transactions-json-value", "version": 2, "id": 2, "schemaType": "JSON", "schema": "{\"type\":\"object\",\"properties\":{\"id\":{\"type\":\"string\"},\"amount\":{\"type\":\"number\"}},\"additionalProperties\":false}"
Use Confluent Control Center to examine schemas and messages.
Messages that were successfully produced also show on Control Center (http://localhost:9021/) in Topics > <topicName> > Messages. You may have to select a partition or jump to a timestamp to see messages sent earlier. (For timestamp, type in a number, which will default to partition
1/Partition: 0, and press return. To get the message view shown here, select the cards icon on the upper right.)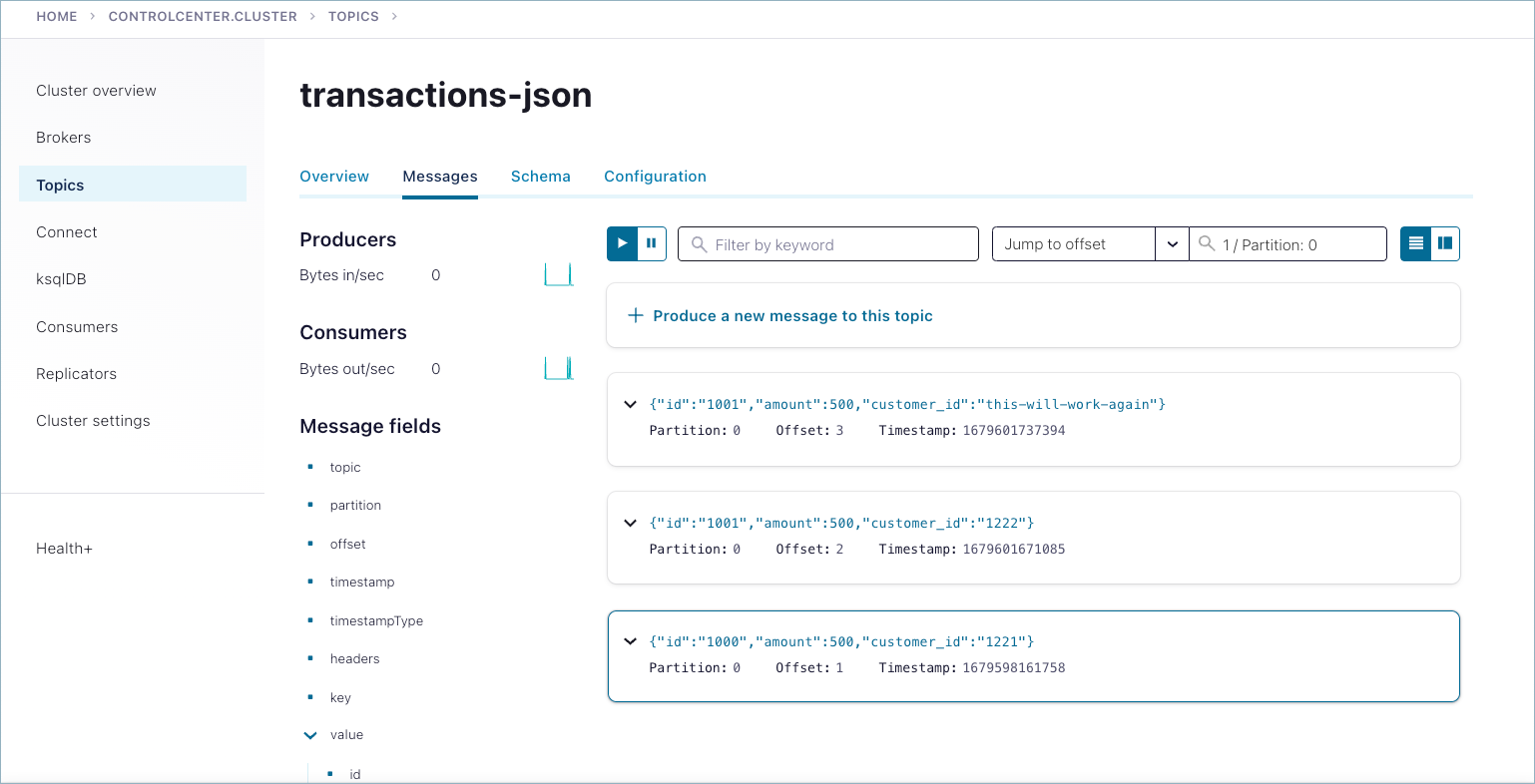
Schemas you create are available on the Schemas tab for the selected topic.
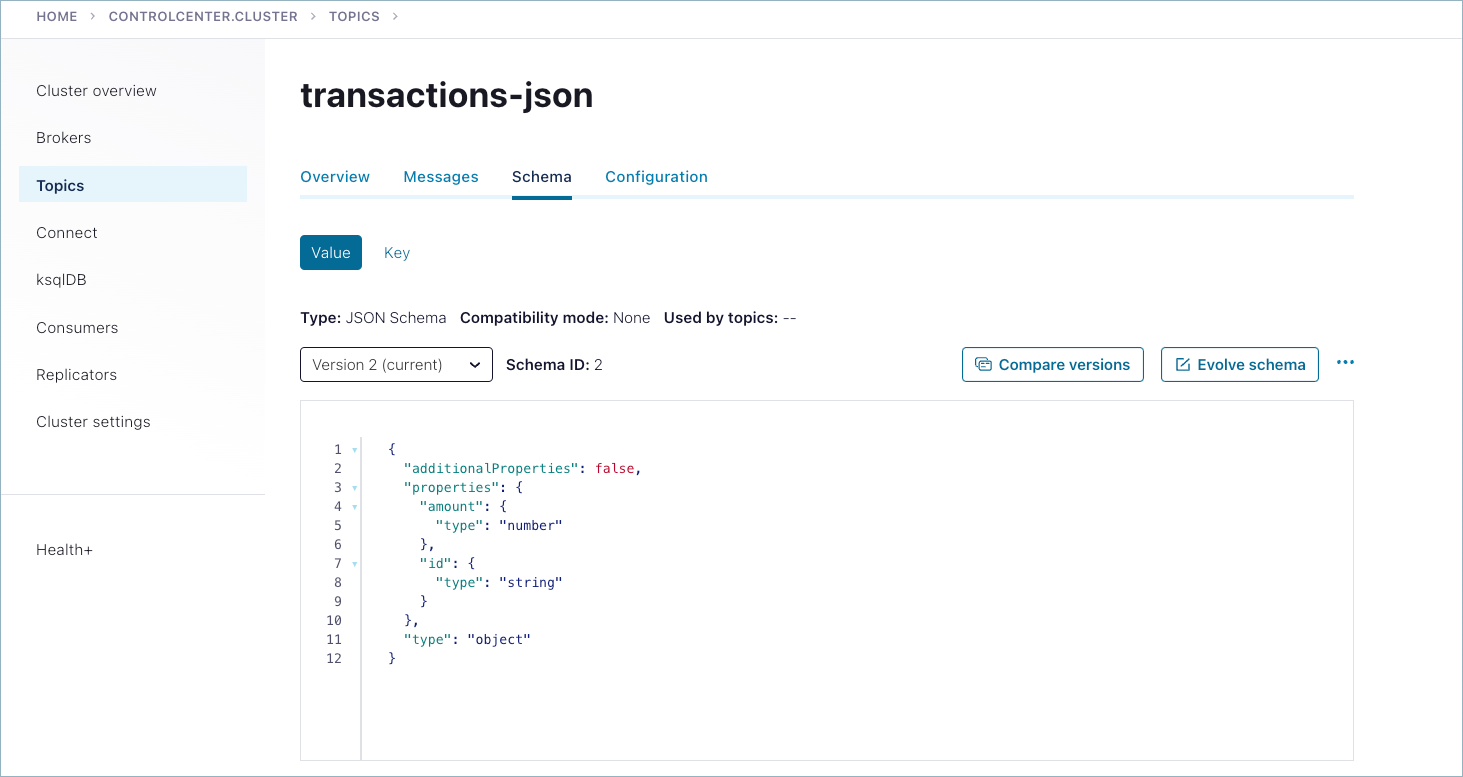
Run shutdown and cleanup tasks.
- You can stop the consumer and producer with Ctl-C in their respective command windows.
- To stop Confluent Platform, type
confluent local services stop. - If you would like to clear out existing data (topics, schemas, and messages) before starting again with another test, type
confluent local destroy.
Create a Kafka topic:
confluent kafka topic create transactions-json --cluster $CLUSTER_ID
Copy the following schema and store it in a file called
schema.txt:{ "type":"object", "properties":{ "id":{"type":"string"}, "amount":{"type":"number"} } }
Run the following command to create a producer with the schema created in the previous step:
confluent kafka topic produce transactions-json \ --cluster $CLUSTER_ID \ --schema "<full path to file>/schema.txt" --schema-registry-endpoint $SCHEMA_REGISTRY_URL \ --schema-registry-api-key $SR_APIKEY \ --schema-registry-api-secret $SR_APISECRET \ --api-key $APIKEY --api-secret $APISECRET \ --value-format "jsonschema"
Your output should resemble:
Successfully registered schema with ID 100001 Starting Kafka Producer. Use Ctrl-C or Ctrl-D to exit.
Tip
- You must provide the full path to the schema file even if it resides in the current directory.
- The examples assume you are using the latest version of the Confluent CLI,
where the deprecated
--sr-endpoint,--sr-api-key, and--sr-api-secretstring have been superseded by the new--schema-registry-endpoint,--schema-registry-api-key, and--schema-registry-api-secret, respectively. If the examples don’t work because these flags aren’t recognized, you must either update to the new CLI, or use the deprecated flags.
Type the following command in the shell, and hit return.
{ "id":"1000", "amount":500 }Open another terminal and run a consumer to read from topic
transactions-jsonand get the value of the message in JSON:confluent kafka topic consume transactions-json \ --cluster $CLUSTER_ID \ --from-beginning \ --value-format "jsonschema" \ --schema-registry-endpoint $SCHEMA_REGISTRY_URL \ --schema-registry-api-key $SR_APIKEY \ --schema-registry-api-secret $SR_APISECRET \ --api-key $APIKEY --api-secret $APISECRET
Your output should be:
{"id":"1000","amount":500}
Use the producer to send another record as the message value, which includes a new property not explicitly declared in the schema.
JSON Schema has an open content model, which allows any number of additional properties to appear in a JSON document without being specified in the JSON schema. This is achieved with
additionalPropertiesset totrue, which is the default. If you do not explicitly disableadditionalProperties(by setting it tofalse), undeclared properties are allowed in records. These next few steps demonstrate this unique aspect of JSON Schema.Return to the producer session that is already running and send the following message, which includes a new property
"customer_id"that is not declared in the schema with which we started this producer. (Hit return to send the message.){"id":"1000","amount":500,"customer_id":"1221"}Return to your running consumer to read from topic
transactions-jsonand get the new message.You should see the new output added to the original.
{"id":"1000","amount":500} {"id":"1000","amount":500,"customer_id":"1221"}The message with the new property (
customer_id) is successfully produced and read. If you try this with the other schema formats (Avro, Protobuf), it will fail at the producer command because those specifications require that all properties be explicitly declared in the schemas.Keep this consumer running.
Update the compatibility requirement for the subject
transactions-json-value.confluent schema-registry subject update transactions-json-value --compatibility "none"
The output message is:
Successfully updated Subject Level compatibility to "none" for subject "transactions-json-value"
Store the following schema in a file called
schema2.txt:{ "type":"object", "properties":{ "id":{"type":"string"}, "amount":{"type":"number"} }, "additionalProperties": false }
Note that this schema is almost the same as the original in
schema.txt, except that in this schemaadditionalPropertiesis explicitly set to false.Run another producer to register the new schema.
Use Ctl-C to shut down the running producer, and start a new one to register the new schema.
confluent kafka topic produce transactions-json \ --cluster $CLUSTER_ID \ --schema "<full path to file>/schema2.txt" --schema-registry-endpoint $SCHEMA_REGISTRY_URL \ --schema-registry-api-key $SR_APIKEY \ --schema-registry-api-secret $SR_APISECRET \ --api-key $APIKEY --api-secret $APISECRET \ --value-format "jsonschema"
Attempt to use this producer to register a new schema, and send another record as the message value, which includes a new property not explicitly declared in the schema.
{ "id":"1001","amount":500,"customer_id":"this-will-break"}This will break. You will get the following error:
Error: the JSON document is invalid
The consumer will continue running, but no new messages will be displayed.
This is the same behavior you would see by default if using Avro or Protobuf in this scenario.
Tip
If you want to incorporate this behavior into JSON Schema producer code for your applications, include
"additionalProperties": falseinto the schemas. Examples of this are shown in the discussion about properties in Understanding JSON Schema.Rerun the producer in default mode as before (by using
schema.txt) and send a follow-on message with an undeclared property.In the producer command window, stop the producer with Ctl+C.
Run the original producer command. Note that there is no need to explicitly declare
additionalPropertiesastruein the schema (although you could), as this is the default.confluent kafka topic produce transactions-json \ --cluster $CLUSTER_ID \ --schema "<full path to file>/schema.txt" --schema-registry-endpoint $SCHEMA_REGISTRY_URL \ --schema-registry-api-key $SR_APIKEY \ --schema-registry-api-secret $SR_APISECRET \ --api-key $APIKEY --api-secret $APISECRET \ --value-format "jsonschema"
Use the producer to send another record as the message value, which again includes a new property not explicitly declared in the schema.
{"id":"1001","amount":500,"customer_id":"this-will-work-again"}Return to the consumer session to read the new message.
The consumer should still be running and reading from topic
transactions-json. You will see following new message in the console.{"id":"1001","amount":500,"customer_id":"this-will-work-again"}More specifically, if you followed all steps in order and started the consumer with the
--from-beginningflag as mentioned earlier, the consumer shows a history of all messages sent:{"id":"1000","amount":500} {"id":"1000","amount":500,"customer_id":"1221"} {"id":"1001","amount":500,"customer_id":"this-will-work-again"}View the schemas that were registered with Schema Registry as versions 1 and 2.
confluent schema-registry schema describe --subject transactions-json-value --version 1
Your output should be similar to the following, showing the
idandamountfields added in version 1 of the schema:Schema ID: 100001 Type: JSON Schema: {"type":"object","properties":{"id":{"type":"string"},"amount":{"type":"number"}}}To view version 2:
confluent schema-registry schema describe --subject transactions-avro-value --version 2
Output for version 2 will include the same fields but include the
additionalPropertiesflag set tofalse:Schema ID: 100002 Type: JSON Schema: {"type":"object","properties":{"id":{"type":"string"},"amount":{"type":"number"}},"additionalProperties":false}Use the Confluent Cloud Console to examine schemas and messages.
Messages that were successfully produced also show on the Confluent Cloud Console (https://confluent.cloud/). in Topics > <topicName> > Messages. You may have to select a partition or jump to a timestamp to see messages sent earlier. (For timestamp, type in a number, which will default to partition
1/Partition: 0, and press return. To get the message view shown here, select the cards icon on the upper right.)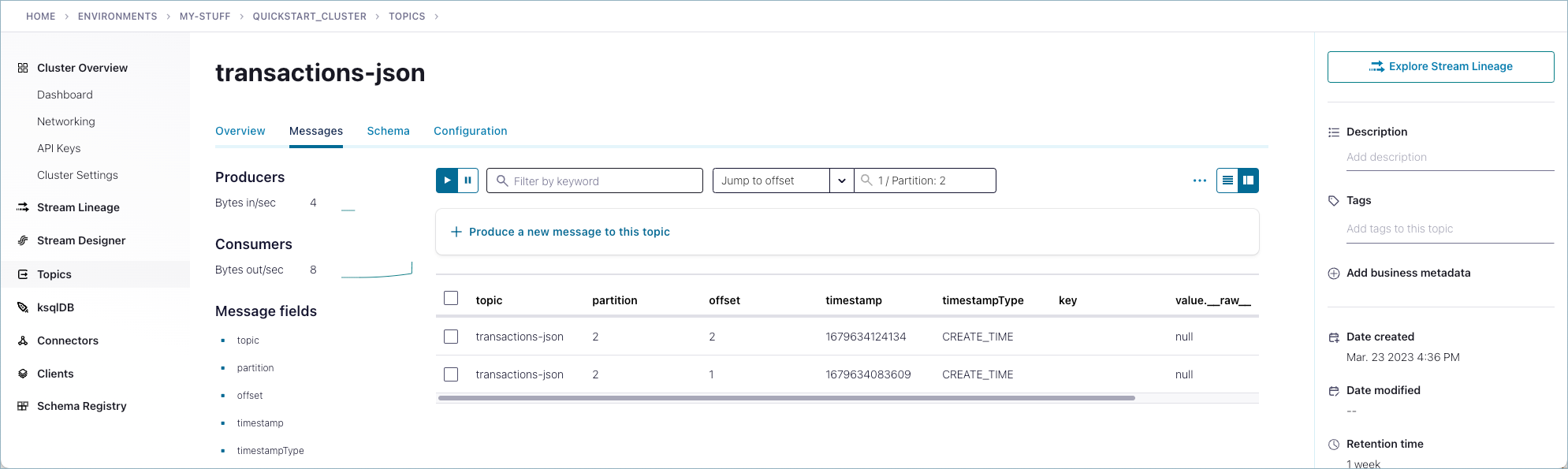
Schemas you create are available on the Schemas tab for the selected topic.
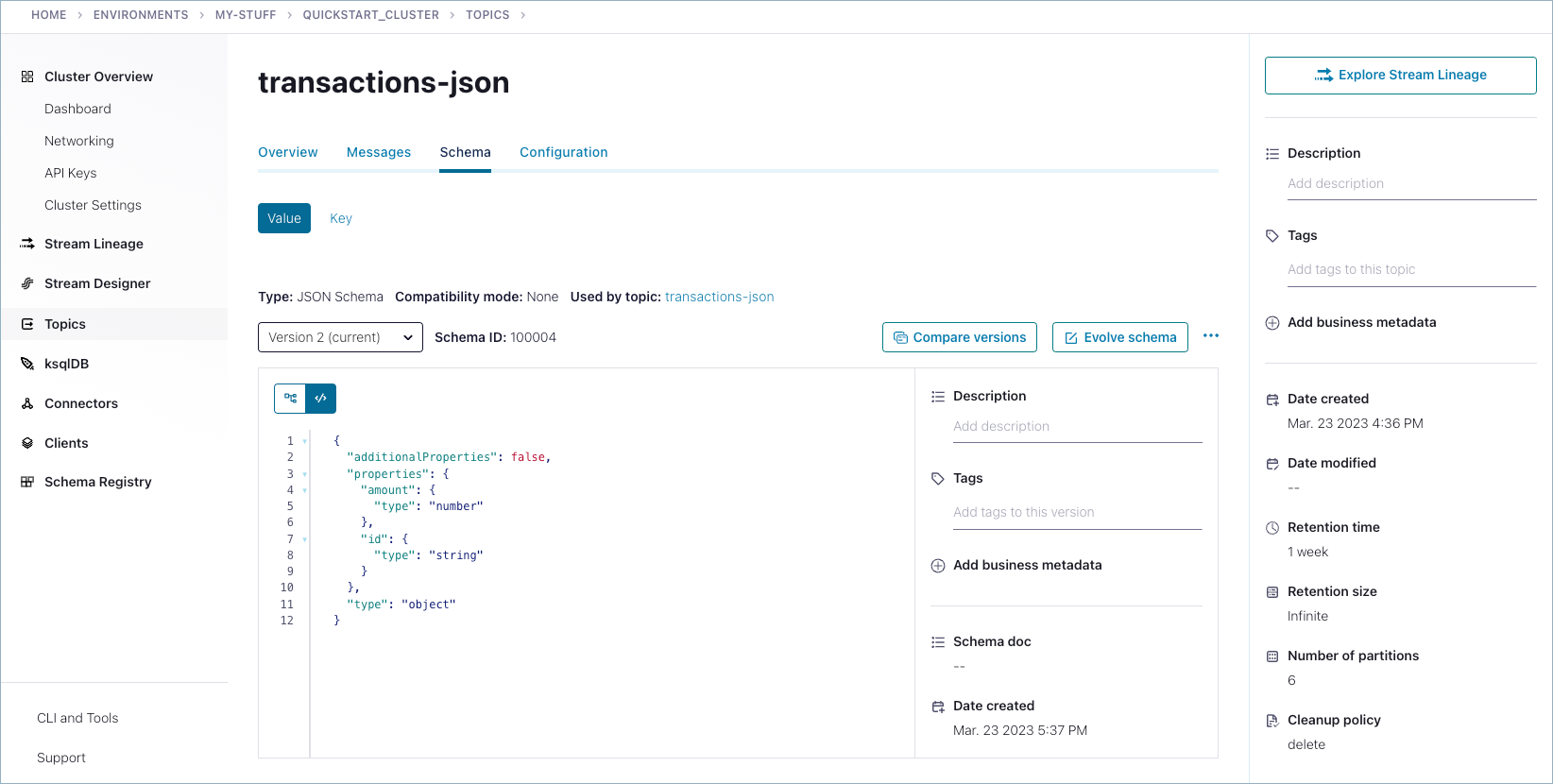
Run shutdown and cleanup tasks.
- You can stop the consumer and producer with Ctl-C in their respective command windows.
- If you were using shell environment variables and want to keep them for later, remember to store them in a safe, persistent location.
- You can remove topics, clusters, and environments from the command line or from the Confluent Cloud Console.
Configurations reference¶
The following configuration properties are available for producers and consumers. These are not specific to a particular schema format, but applicable to any Kafka producers and consumers.
Adding security credentials¶
The test drive examples show how to use the producer and consumer console clients as serializers and deserializers by passing Schema Registry properties on the command line and in config files. In addition to examples given in the “Test Drives”, you can pass truststore and keystore credentials for the Schema Registry, as described in Additional configurations for HTTPS. Here is an example for the producer on Confluent Platform:
kafka-json-schema-console-producer --bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 --topic transactions-json \
--property value.schema='{"type":"object", "properties":{"id":{"type":"string"}, "amount":{"type":"number"} }, "additionalProperties": false}' \
--property schema.registry.ssl.truststore.location=/etc/kafka/security/schema.registry.client.truststore.jks \
--property schema.registry.ssl.truststore.password=myTrustStorePassword
Kafka producer configurations¶
A complete reference of producer configuration properties is available in Kafka Producer Configurations.
Kafka consumer configurations¶
A complete reference of consumer configuration properties is available in Kafka Consumer Configurations.
Schema Registry configuration options¶
A complete reference for Schema Registry configuration is available in the Confluent Platform documentation at Schema Registry Configuration Options.
Using Schema Registry with Connect¶
If you are using serializers and deserializers with Kafka Connect, you will need information on key and value converters. To learn more, see Configuring key and value converters. in the Connect documentation.
Schema references in JSON Schemas¶
Confluent Platform provides full support for the notion of schema references, the ability of a schema to refer to other schemas.
Tip
Schema references are also supported in Confluent Cloud on Avro, Protobuf, and JSON Schema formats. On the Confluent CLI, you can use the --refs <file> flag on confluent schema-registry schema create to reference another schema.
For JSON Schema, the referenced schema is called by using the $ref keyword, followed by a URL or address for the schema you want to refer to:
{ "$ref": "<URL path to referenced schema>" }
For examples of schema references, see Structuring a complex schema on the JSON Schema website, the example given below in Multiple event types in the same topic, and the associated blog post that goes into further detail on this.
Multiple event types in the same topic¶
In addition to providing a way for one schema to call other schemas, schema references can be used to efficiently combine multiple event types in the same topic and still maintain subject-topic constraints.
In JSON Schema, this is accomplished as follows:
Use the default subject naming strategy,
TopicNameStrategy, which uses the topic name to determine the subject to be used for schema lookups, and helps to enforce subject-topic constraints.Use the JSON Schema construct
oneOfto define a list of schema references, for example:{ "oneOf": [ { "$ref": "Customer.schema.json" }, { "$ref": "Product.schema.json" }, { "$ref": "Order.schema.json } ] }When the schema is registered, send an array of reference versions. For example:
[ { "name": "Customer.schema.json", "subject": "customer", "version": 1 }, { "name": "Product.schema.json", "subject": "product", "version": 1 }, { "name": "Order.schema.json", "subject": "order", "version": 1 } ]Configure the JSON Schema serializer to use your
oneOffor serialization, and not the event type, by configuring the following properties in your producer application:auto.register.schemas=false use.latest.version=true
For example:
props.put(KafkaJsonSchemaSerializerConfig.AUTO_REGISTER_SCHEMAS, "false"); props.put(KafkaJsonSchemaSerializerConfig.USE_LATEST_VERSION, "true");
Tip
- Setting
auto.register.schemasto false disables auto-registration of the event type, so that it does not override theoneOfas the latest schema in the subject. Settinguse.latest.versionto true causes the JSON Schema serializer to look up the latest schema version in the subject (which will be theoneOf) and use that for serialization. Otherwise, if set to false, the serializer will look for the event type in the subject and fail to find it. - To learn more, see Auto Schema Registration in the Schema Registry tutorials and Schema Registry Configuration Options for Kafka Connect.
- Setting
JSON Schema compatibility rules¶
The JSON Schema compatibility rules are loosely based on similar rules for Avro, however, the rules for backward compatibility are more complex. In addition to browsing the following sections, see Understanding JSON Schema Compatibility to learn more.
Primitive type compatibility¶
JSON Schema has a more limited set of types than does Avro. However, the following rule from Avro also applies to JSON Schema:
- A writer’s schema of
integermay be promoted to the reader’s schema ofnumber.
There are a number of changes that can be made to a JSON primitive type schema that make the schema less restrictive, and thus allow a client with the new schema to read a JSON document written with the old schema. Here are some examples:
- For string types, the writer’s schema may have a
minLengthvalue that is greater than aminLengthvalue in the reader’s schema or not present in the reader’s schema; or amaxLengthvalue that is less than amaxLengthvalue in the reader’s schema or not present in the reader’s schema. - For string types, the writer’s schema may have a
patternvalue that is not present in the reader’s schema. - For number types, the writer’s schema may have a
minimumvalue that is greater than aminimumvalue in the reader’s schema or not present; or amaximumvalue that is less than amaximumvalue in the reader’s schema or not present in the reader’s schema. - For integer types, the writer’s schema may have a
multipleOfvalue that is a multiple of themultipleOfvalue in the reader’s schema; or that is not present in the reader’s schema.
Object Compatibility¶
For object schemas, JSON Schema supports open content models, closed content models and partially open content models.
- An open content model allows any number of additional properties to appear in a JSON document without being specified in the JSON schema.
This is achieved by specifying
additionalPropertiesas true, which is the default. - A closed content model will cause an error to be signaled if a property appears in the JSON document that is not specified in the JSON schema.
This is achieved by specifying
additionalPropertiesas false. - A partially open content model allows additional properties to appear in a JSON document without being named in the JSON schema, but the
additional properties are restricted to be of a particular type and/or have a particular name. This is achieved by specifying a schema for
additionalProperties, or a value forpatternPropertiesthat maps regular expressions to schemas.
For example, a reader’s schema can add an additional property, say myProperty, to those of the writer’s schema, but it can only be done in a
backward compatible manner if the writer’s schema has a closed content model. This is because if the writer’s schema has an open content model,
then the writer may have produced JSON documents with myProperty using a different type than the type expected for myProperty in the reader’s schema.
With the notion of content models, you can adapt the Avro rules as follows:
- The ordering of fields may be different: fields are matched by name.
- Schemas for fields with the same name in both records are resolved recursively.
- If the writer’s schema contains a field with a name not present in the reader’s schema, then the reader’s schema must have an open content model or a partially open content model that captures the missing field.
- If the reader’s schema has a required field that contains a default value, and the writer’s schema has a closed content model and either does not have a field with the same name, or has an optional field with the same name, then the reader should use the default value from its field.
- If the reader’s schema has a required field with no default value, and the writer’s schema either does not have a field with the same name, or has an optional field with the same name, an error is signaled.
- If the reader’s schema has an optional field, and the writer’s schema has a closed content model and does not have a field with the same name, then the reader should ignore the field.
Here are some additional compatibility rules that are specific to JSON Schema:
- The writer’s schema may have a minProperties value that is greater than the minProperties value in the reader’s schema or that is not present in the reader’s schema; or a maxProperties value that is less than the maxProperties value in the reader’s schema or that is not present in the reader’s schema.
- The writer’s schema may have a required value that is a superset of the required value in the reader’s schema or that is not present in the reader’s schema.
- The writer’s schema may have a dependencies value that is a superset of the dependencies value in the reader’s schema or that is not present in the reader’s schema.
- The writer’s schema may have an additionalProperties value of false, whereas it can be true or a schema in the reader’s schema.
Enum compatibility¶
The Avro rule for enums is directly applicable to JSON Schema.
- If the writer’s symbol is not present in the reader’s
enum, then an error is signaled.
Array compatibility¶
JSON Schema supports two types of validation for arrays: list validation, where the array elements are all of the same type, and tuple validation, where the array elements may have different types. case.
- This resolution algorithm is applied recursively to the reader’s and writer’s array item schemas.
Here are some additional compatibility rules that are specific to JSON Schema:
- The writer’s schema may have a minItems value that is greater than the
minItemsvalue in the reader’s schema or that is not present in the reader’s schema; or amaxItemsvalue that is less than themaxItemsvalue in the reader’s schema or that is not present in the reader’s schema. - The writer’s schema may have a
uniqueItemsvalue of true, whereas it can be false or not present in the reader’s schema.
Union compatibility¶
Unions are implemented with the oneOf keyword in JSON Schema. The rules from Avro can be adapted as follows.
- If the reader’s and writer’s schemas are both unions, then the writer’s schema must be a subset of the reader’s schema.
- If the reader’s schema is a union, but the writer’s is not, then the first schema in the reader’s union that matches the writer’s schema is recursively resolved against it. If none match, an error is signaled.